

FedPAC: Học liên kết cá nhân hóa với feature alignment và cộng tác phân loại
Nội dung
1. Giới thiệu
Trong bài viết này, chúng ta sẽ tìm hiểu về thuật toán FedPAC, một bài báo nổi bật được công bố trong top 5% tại hội nghị ICLR 2023 [1].
Vấn đề với dữ liệu non-IID trong học liên kết:
- Trong học liên kết, phân phối dữ liệu giữa các clients thường không giống hệt nhau (không phải IID hoặc không đồng nhất).
- Các vấn đề với dữ liệu non-IID: Feature distribution drift, label distribution skew, and concept shift.
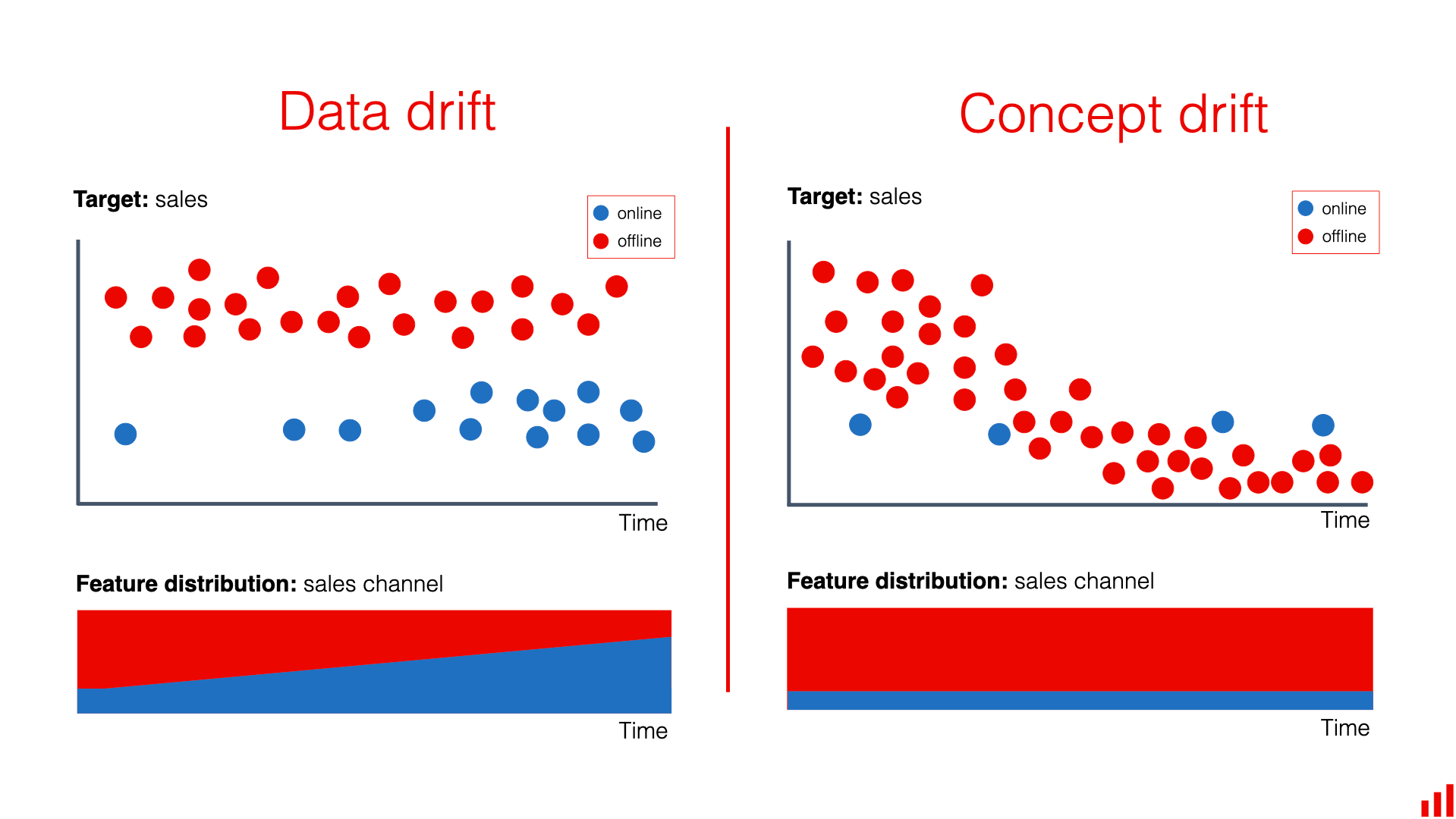 Hình 1. Data drift và Concept drift.
Hình 1. Data drift và Concept drift.
Data drift và Concept drift
Data drift
- Target (Mục tiêu): doanh số
- Mô tả: Dữ liệu về doanh số bán hàng trực tuyến (online) và ngoại tuyến (offline) thay đổi theo thời gian. Sự phân phối đặc điểm (sales channel) cũng thay đổi, với tỉ lệ doanh số offline tăng lên và online giảm xuống theo thời gian.
- Kết quả: Mô hình có thể không hoạt động tốt vì sự thay đổi trong phân phối dữ liệu đầu vào.
Concept drift
- Target (Mục tiêu): doanh số
- Mô tả: Doanh số bán hàng online và offline đều giảm dần theo thời gian. Tuy nhiên, phân phối đặc điểm (sales channel) không thay đổi đáng kể.
- Kết quả: Mô hình cần được cập nhật để phản ánh thay đổi trong mối quan hệ giữa các đặc điểm và mục tiêu.
Nhiều nghiên cứu tập trung vào việc tối ưu hóa các thuật toán học cục bộ bằng cách tận dụng các kỹ thuật điều chỉnh mục tiêu được thiết kế tốt. Ví dụ:
- FedProx (Li và cộng sự, 2020b): Thêm một thành phần gần trong mục tiêu huấn luyện cục bộ để giữ cho tham số cập nhật gần với mô hình gốc đã tải xuống.
- SCAFFOLD (Karimireddy và cộng sự, 2020b): Giới thiệu các biến kiểm soát để điều chỉnh sự dịch chuyển trong các cập nhật cục bộ.
- MOON (Li và cộng sự, 2021b): Sử dụng loss đối nghịch để cải thiện việc học biểu diễn.
Tại sao cần Personalized Federated Learning?
- Dữ liệu non-IID khiến cho việc xây dựng một mô hình toàn cầu duy nhất áp dụng cho tất cả các khách hàng trở nên khó khăn.
- Học liên kết cá nhân hóa đã được phát triển để học một mô hình tùy chỉnh cho từng khách hàng, giúp cải thiện hiệu suất trên dữ liệu cục bộ trong khi vẫn hưởng lợi từ việc học tập hợp tác.
Các phương pháp học liên kết cá nhân hóa (Personalized FL) phổ biến bao gồm:
Hỗn hợp mô hình cộng (Additive model mixture): Thực hiện kết hợp tuyến tính giữa các mô hình cục bộ và toàn cầu.
Ví dụ: L2CD, APFL.Học đa nhiệm với phạt độ không giống nhau của mô hình (Multi-task learning with model dissimilarity penalization).
Ví dụ: FedMTL, pFedMe, Ditto.Tách tham số của bộ trích xuất đặc trưng và bộ phân loại (Parameter decoupling of feature extractor and classifier).
Ví dụ: FedPer, LG-FedAVG, FedRep.Học liên kết nhóm (Clustered FL): Gom nhóm các khách hàng tương tự và học nhiều mô hình toàn cầu trong nhóm.
Ví dụ: FedFoMo, Fed AMP.
Các phương pháp học liên kết (FL) khác cho từng khách hàng cụ thể bao gồm:
- FedGP: Dựa trên quá trình Gaussian.
- pFedHN: Kích hoạt bởi hypernetwork ở phía máy chủ.
- FedEM: Học một hỗn hợp của nhiều mô hình toàn cầu.
- Fed-RoD: Sử dụng softmax cân bằng để học mô hình chung và softmax gốc cho các đầu ra cá nhân hóa.
- FedBABU: Giữ nguyên bộ phân loại toàn cầu trong quá trình học biểu diễn đặc trưng và thực hiện điều chỉnh cục bộ bằng cách tinh chỉnh.
- kNN-Per: Áp dụng tổ hợp giữa mô hình toàn cầu và các bộ phân loại kNN cục bộ để có hiệu suất cá nhân hóa tốt hơn.
 Hình 2. Ứng dụng của học không giám sát.
Hình 2. Ứng dụng của học không giám sát.
Representation Learning và Downstream Application
- Representation Learning: Tự động học các tính năng hữu ích từ dữ liệu thô.
- Downstream Application: Sử dụng các biểu diễn đã học được từ học biểu diễn để giải quyết các nhiệm vụ hoặc vấn đề thực tế.
Multi-Tasks Learning
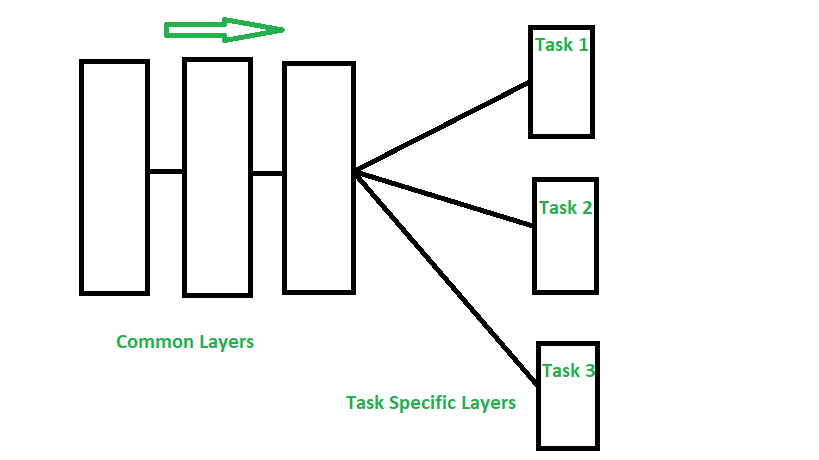 Hình 3. Multi-Tasks Learning.
Hình 3. Multi-Tasks Learning.
Hình ảnh trên minh họa kiến trúc học sâu cho việc học đa nhiệm (multi-task learning).
Common Layers (Các lớp chung): Các lớp này chia sẻ giữa các nhiệm vụ khác nhau. Chúng chịu trách nhiệm trích xuất các đặc trưng chung từ dữ liệu đầu vào.
Task Specific Layers (Các lớp đặc thù cho từng nhiệm vụ): Các lớp này chuyên biệt cho từng nhiệm vụ cụ thể. Sau khi đi qua các lớp chung, đầu ra sẽ được chia thành các nhánh riêng, mỗi nhánh tương ứng với một nhiệm vụ cụ thể như Task 1, Task 2, và Task 3.
Kiến trúc này cho phép mô hình tận dụng thông tin từ các nhiệm vụ khác nhau, cải thiện hiệu suất tổng thể bằng cách học các đặc trưng chung đồng thời vẫn đảm bảo tính chuyên biệt cho từng nhiệm vụ.
COntribute chính trong bài báo:
- Chủ yếu xem xét kịch bản label distribution shift và classification task.
- Nghiên cứu học liên kết từ góc độ học đa nhiệm (multi-task learning) bằng cách tận dụng cả shared representation và inter-client classifier.
2. Proposed framework
Problem setup
Xét:
- Có $m$ khách hàng (clients) và một máy chủ trung tâm.
- $X$ là không gian đầu vào, $Y$ là không gian nhãn, và $K$ là số lượng loại (categories).
- Mỗi khách hàng $i$ có dữ liệu riêng của mình $P^{(i)}_{XY}$ và giả định rằng $P^{(i)} \neq P^{(j)}$.
- Hàm mất mát (loss function) $\ell : X \times Y \rightarrow \mathbb{R}^+$ được cung cấp bởi mô hình cục bộ $w_i$.
- $W = (w_1, w_2, \ldots, w_m)$.
Mục tiêu tối ưu hóa được biểu diễn như sau:
\[\min_{\mathbf{W}} \left\{ F(\mathbf{W}) := \frac{1}{m} \sum_{i=1}^{m} \mathbb{E}_{(x, y) \sim P^{(i)}_{XY}} \left[ \ell(w_i; x, y) \right] \right\}\]- Phân phối ẩn thực sự không thể tiếp cận được. Mục tiêu đạt được bằng phương pháp giảm thiểu rủi ro kinh nghiệm (ERM).
- Giả sử mỗi client có quyền truy cập vào $n_i$ điểm dữ liệu IID được lấy mẫu từ $P^{(i)}_{XY}$, được ký hiệu bởi \(D_i = \{(x^{(i)}_l, y^{(i)}_l)\}_{l=1}^{n_i}, \hat{P}^{(i)}_{XY}\) Giả sử \(\hat{P}^{(i)}_{Y} = P^{(i)}_{Y}\)
Sharing feature representation
Hàm feature embedding $f: \mathcal{X} \rightarrow \mathbb{R}^d$ là một mạng học được tham số hóa bởi $\Theta_f$ và $d$ là chiều của $z$, $z = f(x)$, $\hat{y} = g(z)$.
$g(z)$ được tham số hóa bởi $\Phi_g$, toàn bộ tham số mô hình sẽ là $\mathbf{w} = {f, \Phi}$.
Việc chia sẻ các lớp đặc trưng có thể giảm thiểu việc thiếu dữ liệu của các client gây ra hiện tượng overfitting, nhưng cập nhật cục bộ làm tăng overfitting và đa dạng tham số.
→ Một thuật ngữ điều chuẩn mới được đề xuất để giải quyết vấn đề này.
Các client cập nhật mô hình cục bộ với một thuật ngữ điều chuẩn mới kết hợp các centroid đặc trưng toàn cục để cải thiện khả năng tổng quát hóa.
- $f_{\phi_i}(x_j)$ là nhúng đặc trưng cục bộ của điểm dữ liệu $x_j$.
- $c_{y_j}$ là centroid đặc trưng toàn cục tương ứng của lớp $y_j$.
- $\lambda$ là siêu tham số để cân bằng giữa mất mát có giám sát và mất mát điều chuẩn.
Classifier collaboration
- Tăng cường hiệu suất bằng cách gộp các bộ phân loại từ các client tương tự, giảm phương sai và cải thiện các mô hình cục bộ thông qua việc chuyển giao kiến thức giữa các client.
- Để đánh giá độ tương đồng và khả năng chuyển giao giữa các client, chúng tôi thực hiện một tổ hợp tuyến tính của các bộ phân loại đã nhận được cho từng client $ i $ nhằm giảm thiểu tổn thất kiểm tra cục bộ:
- Mỗi hệ số $ \alpha_{ij} \geq 0 $ được xác định bằng cách tối thiểu hóa tổn thất kiểm tra kỳ vọng cục bộ thông qua một bài toán tối ưu:
- Để tăng cường sự hợp tác, các hệ số $ \alpha_i $ cần được cập nhật thích ứng trong quá trình huấn luyện.
3. Algorithm design
Local training procedure
Trong mỗi vòng huấn luyện cục bộ $t$, mô hình được cập nhật với tổng hợp toàn cầu nhận được cho các lớp biểu diễn và điều chỉnh các bộ phân loại riêng tư tương ứng, sau đó áp dụng phương pháp gradient descent ngẫu nhiên để huấn luyện cả hai phần của tham số mô hình.
- Bước 1: Cố định $\theta_i $, Cập nhật $ \phi_i $. Huấn luyện $ \phi_i $ trên dữ liệu riêng tư bằng phương pháp gradient descent trong một epoch:
trong đó $\xi_i $ biểu thị mini-batch của dữ liệu, $ \eta_g $ là tốc độ học cho việc cập nhật classifier.
- Bước 2: Cố định $ \phi_i $ mới, Cập nhật $ \theta_i $. Sau khi có được classifier mới cục bộ, ta tiếp tục huấn luyện bộ trích xuất đặc trưng cục bộ dựa trên cả dữ liệu riêng tư và các trọng tâm đặc trưng toàn cục trong nhiều epoch:
trong đó $ \eta_f $ là tốc độ học để cập nhật các lớp biểu diễn, $ c^{(t)} \in \mathbb{R}^{K \times d} $ là tập hợp các vector trọng tâm đặc trưng toàn cục cho mỗi lớp, và \(K = |\mathcal{Y}|\) là tổng số lớp.
Trước khi cập nhật bộ trích xuất đặc trưng cục bộ, mỗi client trích xuất các thống kê đặc trưng cục bộ $\mu_i^{(t)}$ và $V_i^{(t)}$ để ước tính trọng số kết hợp của bộ phân loại. Sau khi cập nhật bộ trích xuất, các trọng tâm đặc trưng cục bộ cho mỗi lớp được tính toán.
\[\hat{c}_{i,k}^{(t+1)} = \frac{\sum_{l=1}^{n_i} \mathbb{1}(y_l^{(i)} = k) f_{\theta_i^{(t+1)}}(x_l^{(i)})}{\sum_{l=1}^{n_i} \mathbb{1}(y_l^{(i)} = k)}, \forall k \in [K].\]Global aggregation
Biểu diễn đặc trưng toàn cục. Giống như các thuật toán phổ biến, server thực hiện trung bình có trọng số của các lớp biểu diễn cục bộ với mỗi hệ số được xác định bởi kích thước dữ liệu cục bộ.
\[\tilde{\theta}^{(t+1)} = \sum_{i=1}^{m} \beta_i \theta_i^{(t)}, \quad \beta_i = \frac{n_i}{\sum_{i=1}^{m} n_i}.\]Kết hợp bộ phân loại. Server sử dụng các thống kê đặc trưng nhận được để cập nhật vector trọng số kết hợp $\alpha_i$ bằng cách giải (11) và thực hiện kết hợp bộ phân loại cho mỗi client $i$.
Cập nhật trọng tâm đặc trưng toàn cục. Sau khi nhận được các trọng tâm đặc trưng cục bộ, thao tác tổng hợp trọng tâm sau đây được thực hiện để tạo ra một trọng tâm toàn cục ước lượng $c_k$ cho mỗi lớp $k$.
\[c_k^{(t+1)} = \frac{1}{\sum_{i=1}^{m} n_{i,k}} \sum_{i=1}^{m} n_{i,k} \hat{c}_{i,k}^{(t+1)}, \quad \forall k \in [K].\]4. Thử nghiệm
Experiments setup
-Dữ liệu: EMNIST, Fashion-MNIST, CIFAR-10, và CINIC-10.
-Phân chia dữ liệu: - Khách hàng có kích thước dữ liệu đồng đều, với 20% được chọn ngẫu nhiên và phần còn lại từ các lớp chiếm ưu thế. - Khách hàng được nhóm theo các lớp chiếm ưu thế chung, với dữ liệu huấn luyện cục bộ nhỏ. - Dữ liệu kiểm tra trùng khớp với dữ liệu huấn luyện.
Phương pháp so sánh: Các phương pháp cơ bản bao gồm Local-only, FedAvg, FedAvgFT, APFL, pFedMe, Ditto, LG-FedAvg, FedPer, FedRep, FedBABU, Fed-RoD, kNN-Per, FedFomo, và pFedHN.
Cài đặt huấn luyện:
- SGD mini-batch được sử dụng làm bộ tối ưu cục bộ cho tất cả các phương pháp, với 5 vòng huấn luyện cục bộ.
- 200 vòng giao tiếp toàn cầu được thiết lập cho tất cả các bộ dữ liệu.
Results
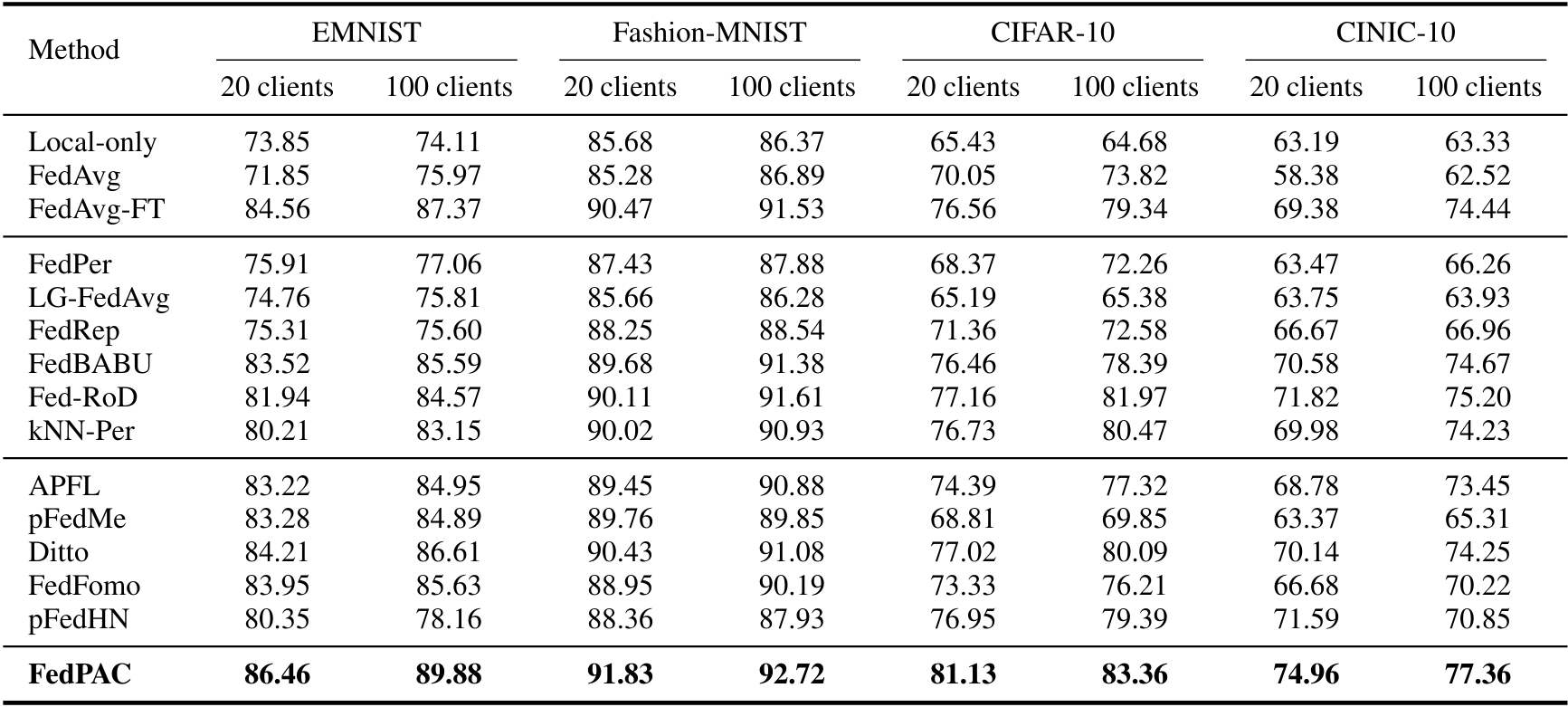 Hình 4. So sánh test accuracy (%) trên các tập dữ liệu khác nhau.
Hình 4. So sánh test accuracy (%) trên các tập dữ liệu khác nhau.
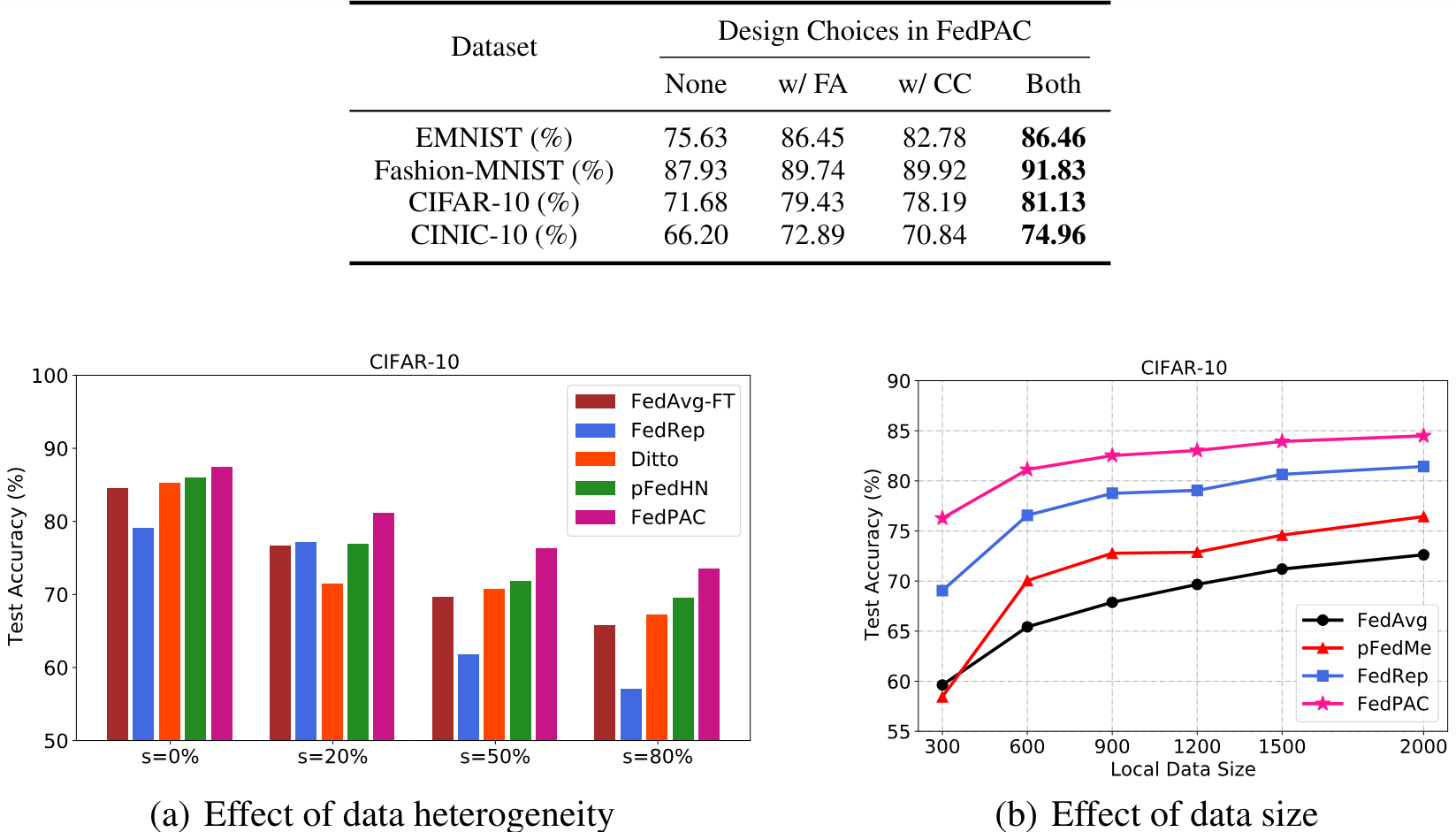 Hình 5. So sánh hiệu suất trên tập dữ liệu CIFAR-10 với mức độ đa dạng dữ liệu và kích thước dữ liệu cục bộ khác nhau.
Hình 5. So sánh hiệu suất trên tập dữ liệu CIFAR-10 với mức độ đa dạng dữ liệu và kích thước dữ liệu cục bộ khác nhau.
 Hình 6. Test accuracy (%) với concept shift.
Hình 6. Test accuracy (%) với concept shift.
5. Tham khảo
[1] Momentum Contrast for Unsupervised Visual Representation Learning, Kaiming He et al.